
I often get asked by clients about some of the new confusing vocabulary in the cloud space. Vocabulary such, as Hybrid Cloud, Hybrid IT, Multi-Cloud, Cloud Native, Edge Computing, Distributed Clouds .. etc. What do they mean?
I will explain those and cover their main business uses cases
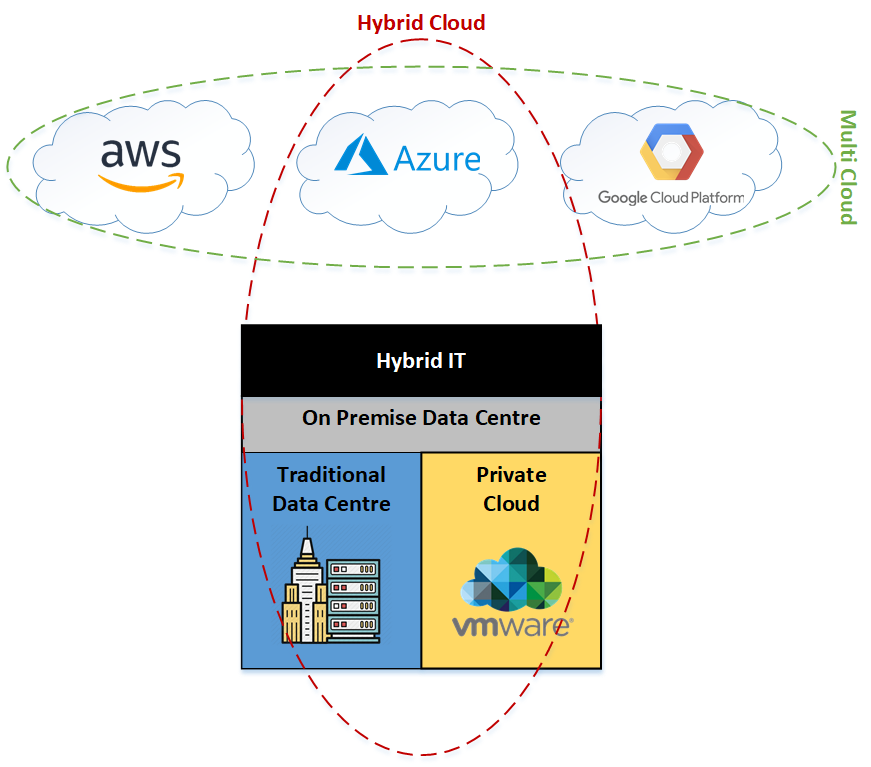
Hybrid Cloud
The work Hybrid according to Oxford Dictionary is “a thing made by combining two different elements” and this is what we get with this type of architecture. We are integrating on premise data centre, often a private cloud, with a public cloud. An example would be integrating a VMware private cloud on premise, with a public cloud such as Azure or AWS.
However, today we have a new type of Hybrid cloud. Many public cloud providers are providing what many call public cloud in a can. For example, Azure Stack and AWS Outpost, provide you a private cloud on premise that is a smaller version of Azure or AWS. The reason this new Hybrid Cloud is gaining traction in the market place, is they are much easier to deploy than traditional private clouds (Openstack and VMware) and offers same look and feel as the public cloud.
Multi-Cloud
Again, using Oxford Dictionary, the definition of multi is “more than one” and in multi-cloud architecture, we are utilising more than one public cloud. For example, in addition to your on premise data centre (or without it), you also have Azure and AWS your public clouds. What we see often, is clients starting with one public cloud, then as they mature, they adopt a second public cloud. Make no mistake, one public cloud adds extra layers of complexity, having multiple clouds will certainly double or triple the complexity. Therefore, a strong justification for multi-cloud usage is needed. Most common reasons I see for using multi-cloud are:
- Use different public cloud for their specific advanced services
- Use multiple-clouds to offer portability and to avoid lock-in.
Hybrid IT
Once IT starts offering traditional data centre and cloud services, they have reached the Hybrid IT phase. Now IT becomes the single pane of glass, decoupling users from the hybrid resources they are consuming, whether it is on premise or hosted in public cloud.
Cloud Native
This is a fairly new term that has become an all-encompassing term for new and upcoming cloud technologies for application development. Cloud native applications utilise technologies such as Containers, Serverless, Analytics, etc., combined with the cloud’s API driven design to enable high level of large scale automation. Cloud native is the next evolution from applications running on IaaS.
Edge Computing
Edge computing is a fairly new buzzword, but what does it mean? The “edge” refers to edge of corporate network to the cloud. The edge refers to physical location where infrastructure is located near the data source. The data is processed near where it is generated instead of relying on the compute resources at somewhat centralised cloud data centre. Why would you use edge computing?
There is an explosion in the number of Internet of Things (IoT) devices and the massive amount of data they generate at the edge of the network. Transferring that massive amount of data to central cloud computing data centre for capturing, saving and processing has become a major bottleneck due to bandwidth limitations. Using the cloud adds another challenge when you have applications that demand near real time processing. Using the cloud introduces latency which can be avoided with edge computing.
Latency and bandwidth: With explosion in the number of IoT devices and the massive amounts of data they generate, all that data near source cuts down on latency and bandwidth consumption. This is critical for applications that require near real time processing.
There are many emerging use cases for edge computing. For example, finance firms dealing in hedge funds, cannot afford a few milliseconds in delayed transaction, as it can result in substantial losses. As a result, many have adopted edge computing, where compute infrastructure is placed near the stock exchange (source of data) to keep latency to a minimum.
Many think cloud and edge as two alternatives when in reality, they are complimentary of each other.
Distributed Cloud
The large public cloud providers are adopting distributed architecture by extending their services to cover edge computing. For example AWS has Greengrass and Azure has IoT edge solutions that help with management and monitoring of IoT devices. The future direction of distributed cloud will see resources automatically placed and consumed in multiple physical locations (Cloud, On-Premise, Edge) based on requirements such as latency, security, etc.
Cloud Repatriation
The definition of Repatriation is returning something to the source of its origin. In the context of cloud, Cloud Repatriation is the return of workload from cloud to its on premise data centre. What is behind this limited scale trend?
Many organisations today, have adopted everything cloud policy, resulting in mass migrations to public cloud. However, as Hybrid – Multi Cloud become the standard, many have realised not all workloads are created equal, as each might have different requirements and constraints. For example, certain workloads have very low latency requirements and high bandwidth demands, and if the data is back on premise, bottlenecks could happen, resulting in degraded performance.
Data sovereignty and security is another reason behind data and applications moving back home, to gain better control and visibility.
Finally, cost is another reason why certain workloads are moving back home. Cost savings are not always a major benefit of cloud, despite common thinking. With the advancement of cloud like capabilities in on premise data centres, many perceive it more economical to move it back home.
Thank you for reading & sharing
Nick






Jim
September 10, 2019I have found your hybrid IT multi cloud diagram and explanation great. Thank you.